Automatic generation of C++ code for process models – 3 of 3
Here we are at the last installment of this series of posts on automatic code generation, which started out as a journey to make the workflow for coding process models in C++ with the LIBPF™ library easier and less boring.
In part one we covered the JSON representation of process models, its JSON schema and C++ code generation with a command-line tool using the jinja2 template engine.
In part two we made the code generation interactive with the LIBPF™ model wizard, a free and open source client-side, browser-based interactive JSON editing + code generation tool that can be used online or run locally.
In this last part of the series we will present an example of the complete model development workflow using the LIBPF™ model wizard, and close up with some philosophical considerations.
An example
To demonstrate the complete model development workflow with the LIBPF™ model wizard, we’ll pick up an integrated distillation / pervaporation process to purify a methylbutynol (MBI) / water mixture, as laid out in a recent United States Patent Application by Stefan Ottiger, Thomas Scholl, Stefan Stoffel, Klaus Kalbermatter, Andreas Klein and Kishore Nedungadi all at Lonza Ltd.
We refer to the left-hand part of figure 1 of the application (let’s neglect the subsequent purification steps):
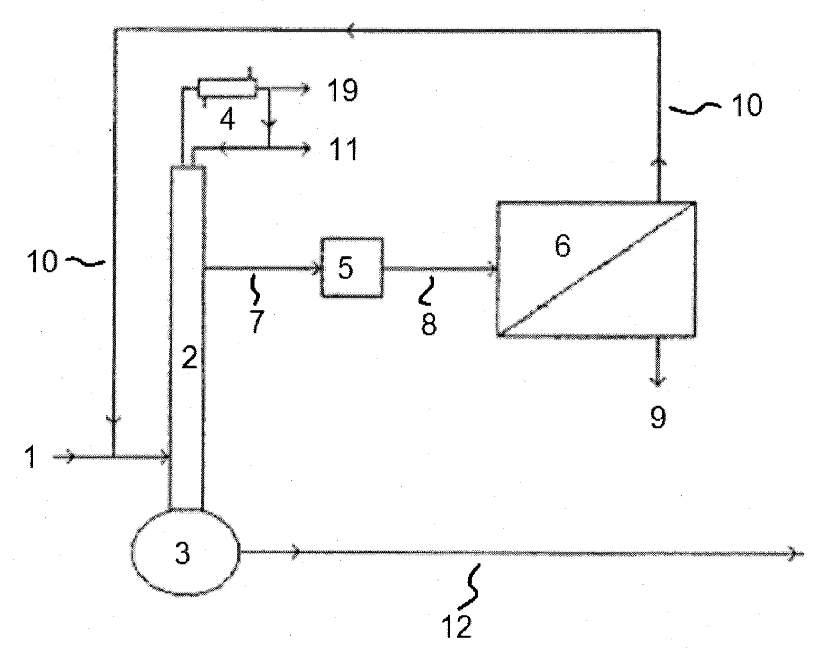
This is the legend:
- 1: feed composition comprising methylbutynol and water
- 2: distillation column
- 3: column bottom
- 4: column head
- 5: sidestream collection tank
- 6: pervaporation device
- 7: sidestream removal
- 8: sidestream to pervaporation
- 9: permeate enriched in water
- 10: retentate dewatered and enriched in methylbutynol
- 11: low-boiling components which are liquid at room temperature (acetone) removal
- 12: column bottom comprising a high ratio of methylbutynol
- 19: incondensables (mostly ammonia) removal in gaseous form
Before we can create a model for this process in LIBPF™, we need to “translate” this block diagram in a process flowsheet proper.
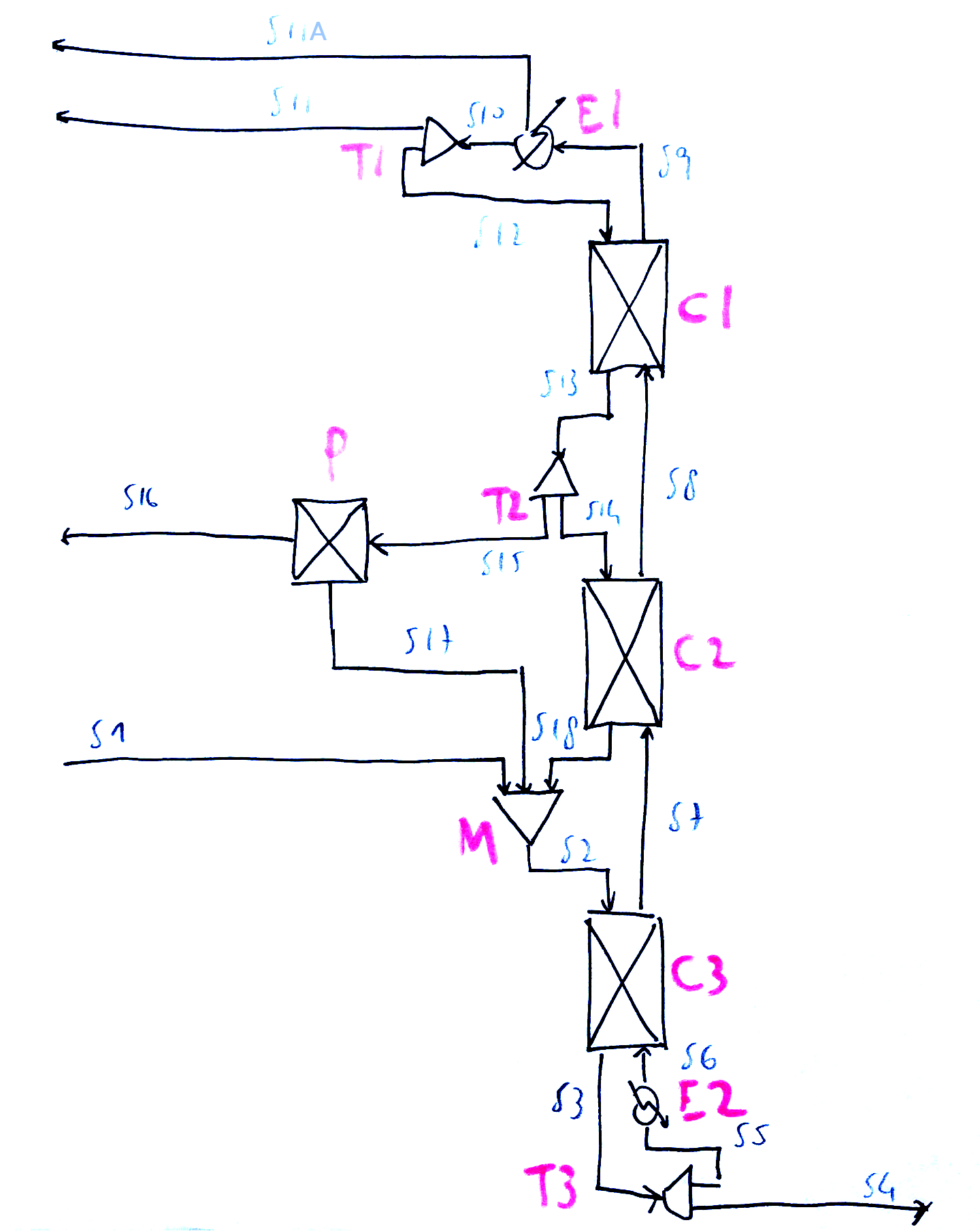
This requires to break down some units and add other units.
In fact we need break down the column in three sections (C1, C2 and C3) to insert the feed and extract the side-draw.
Furthermore we need to add the following units:
- a feed mixer M to mix the fresh feed with the retentate recycle; we can use the same to mix the total feed with the upper tray liquid)
- a tee T1 to partition the condensate between reflux and distillate product
- a tee T2 to partition the tray liquid between side-draw and the liquid that is allowed to proceed to the next stage
- a tee T3 to partition the column last tray liquid between bottom product and boil-up
This is the resulting process flowsheet diagram as a paper & pencil sketch:
LIBPF™ Model Wizard to the rescue
We can now use the LIBPF™ Model Wizard to define this flowsheet.
This 3-minute video shows the procedure (some parts of the procedure are fast-forwarded – in real life it takes about 20 minutes):
Here are the four main required steps:
- clear the form
- type the front-matter, in particular the model name which will become the name of the class and of the generated files
- define the unit operations, for each of them you need to assign a name, an optional description and the type; to decide which types to use, check the LIBPF SDK documentation for the available unit operations, or use “Other” if you’re uncertain
- create the connections between the units, by defining the material streams; for each stream besides name, optional description, and type you also need to specify units and ports for the source and destination of the stream; for the source and destination units you pick them from the list of units (based on the names you previously assigned) but there are also two special units: “source” (use as source unit to indicate that a stream is a feed stream) and “sink” (use as destination unit to indicate that a stream is a product from the flowsheet); for the ports, you should check the unit documentation since each unit has different available ports – often inlet ports are called “in” and outlet ports are called “out” or some specific name such as “vapor”, “liquid”, “permeate” or “retentate”; for the available stream types check the LIBPF SDK documentation
In this example we are using 5 different unit types:
- three “ColumnSections”, which are counter-current multi-stage, adiabatic, vapor-liquid separations
- a “Mixer”, which does just that: mix the inlet streams;
- three “Dividers” for the tees which split their inlet without changing its state and composition;
- “Other” for the pervaporation unit;
- and “FlashDrum” for two single-stream heat exchangers;
and 3 stream types:
- “StreamLiquid” for liquid-only streams;
- “StreamVapor” for vapor-only streams;
- and “StreamNrtl1LiquidVapor” for two-phase, vapor-liquid streams with the Non Random Two Liquids (NRTL) activity coefficient model for the phase equilibrium.
The end product of the LIBPF™ model wizard is a JSON description of the PervaDist process, but a more intuitive view is offered by the generated Process Flowsheet Diagram preview:
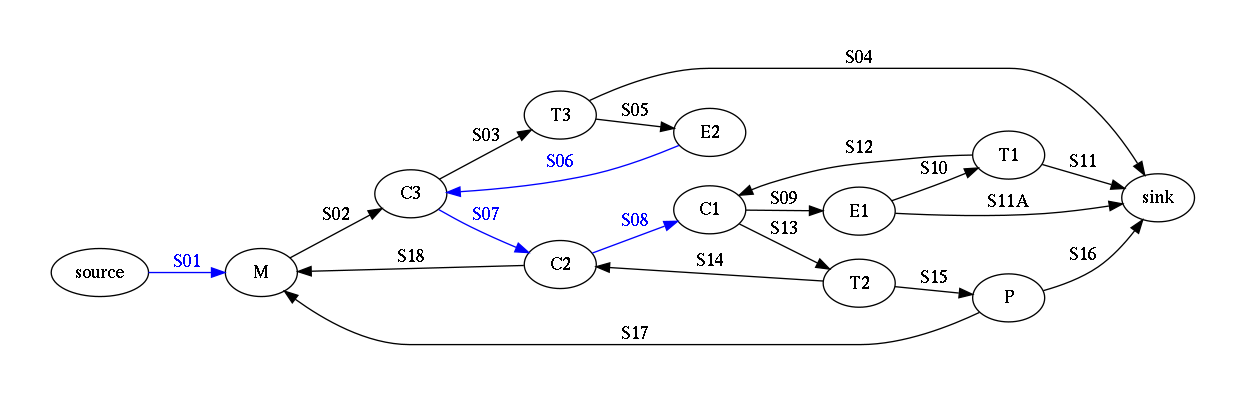
To move forward we will use the generated C++ code: interface, implementation and driver.
Show me the code, Luke
So let’s get the C++ code generated by the LIBPF™ Model Wizard and use it set up a model in the LIBPF™ SDK.
Open a terminal window, (on Windows, that would be a Git Bash shell), move to the location of the LIBPF SDK (we assume it has been installed in the Desktop), then invoke the create_model_skeleton script with the name of the model we want to create as argument:
cd Desktop/LIBPF_sdk ./scripts/create_model_skeleton.sh PervaDist
Be careful to use here the very same name you used in the model wizard (“PervaDist” in this example).
This command will create a PervaDist directory, with src and include sub-directories in accordance with the source code directory structure standard.
In those directories you will find three files:
- include/PervaDist.h where you will copy-paste the interface from the LIBPF™ Model Wizard, completely overwriting the file content;
- src/PervaDist.cc where you will copy-paste the implementation from the LIBPF™ Model Wizard, completely overwriting the file content;
- src/PervaDistDriver.cc where you will copy-paste the driver from the LIBPF™ Model Wizard, placing it in the body of the “initializeKernel” function, replacing the placeholder text under the comment line “register the provided types”.
To perform the copy-paste, it’s easier to use an Integrated Development Environment (IDE) that will also make things easier during further manipulation of the code.
The supported IDEs are:
-
Qt Creator (all platforms): to open Qt Creator, just open the PervaDist.pro project file in the “PervaDist” directory by double-clicking;
-
Xcode (on Apple OS X): enter the “PervaDist” directory then generate the project file with qmake:
cd PervaDist /Qt/5.5/clang_64/bin/qmake -spec macx-xcode
this command will generate the “pervadist.xcodeproj” Xcode project file file in the “PervaDist” directory. You can open that with Xcode by double-clicking;
-
and Microsoft Visual Studio (on Microsoft Windows): enter the “PervaDist” directory then generate the project file with qmake:
cd PervaDist /Qt/Qt5.5.5/5.5/msvc2013/bin/qmake -tp vc
this command will generate the “pervadist.vcproj” Visual Studio project file in the “PervaDist” directory. You can open that with Visual Studio by double-clicking.
These three videos show this procedure in practice on OS X with Qt Creator or with Xcode, and on Windows with Microsoft Visual Studio:
Next steps
The generated C++ code will compile and link, but it not work out of the box: consider it a starting point !
From here you still need to do some work to complete your model – these are the minimum required steps:
- in the driver:
- define the components
- provide additional details for the service / kernel in the instantiation of the KernelImplementation object, replacing the ellipsis (…)
- if you are using any string enumerator, populate them
- if you used the “Other” type placeholder, replace that with whatever model you need
- if you have defined any integer or string option, make use of their values to trigger logic or calculations as required
- complete the implementation of the setup function with:
- settings for input variables: feed streams
- setting input variables: operating conditions for the unit operations
- initializing cut streams (if any)
- supply the model icon, by default it should be named PervaDist.svg (where PervaDist is your model name).
Finally there are some additional, optional steps that are sometimes required:
- provide a non-dummy implementation for the mandatory member functions makeUserEquations, pre and post
- implement the non-mandatory functions supportsSimultaneous, maximumIterations and sequential
- the videos cover the basic use case where you only want your service / kernel to support a single model, but actually it is possible to pack several models inside a kernel; the workflow to add new models and the associated files to a LIBPF project is covered by this old (but still relevant !) blog post.
Finale: some philosophy
In this video:
you can see Bret Victor, a famous user interface designer performing as a young 1973 egghead in a white shirt and black tie, talking about the future of programming in 2013 as if it were 1973. The presentation (done with an overhead projector) pushes the key message that already back in 1973 you could tell the future of programming would be setting concurrent goals and constraints by direct manipulation of data as spatial representations. Victor regrets it’s 2013 (now it’s 2015!) and we’re still coding sequential procedures as sequences of symbols.
As much as I agree with Bret Victor that creative processes are visual, that does not necessary mean that the user interface should be visual in all cases: a textual representation is more distant from the way we create, but it can be formally compared, exchanged and processed. The move from symbolic to visual manipulation has been the marketing mantra of the IT industry for decades: it goes in the direction of user friedliness and increased usability. While easy to use interfaces can be a blessing for commoditized, consumer-oriented software, history has shown that there are domains (music, mathematics, and – we argue – process modeling) where visual interfaces can be of help, but do not solve all the problems !
When you use LIBPF™ to develop process models, you declaratively specify your goals and constraints using a symbolic, textual programming language (C++), but without specifying the procedure and the sequence to solve them. Additionally, with the LIBPF™ Model Wizard you now have a tool which can make it easier and less boring to set up the process models in C++ !