LIBPF® database interface manual
Introduction
Intended audience
System integrators who wish to develop solutions based on the modeling of industrial continuous processes with the LIBPF® enabling technology, in particular solutions where a direct interface to the database used by LIBPF® for object persistnecy is required.
Scope
This document is the database interface manual for LIBPF®.
Models developed with LIBPF® are not saved to a file but are rather persisted to a relational database.
The high-level design bases of the LIBPF® database interface are:
-
provide the ability to store and retrieve the state of an object to a database
-
avoid data duplication
-
optimize persistency performance
-
portability: drivers are available for ODBC on Windows, sqlite and postgresql.
Prerequisites
-
having access to a LIBPF® model running as a service in the public/private cloud configured for the LIBPF® RESTful Model User API
-
knowledge of the RESTful API design principles and access to one of the RESTful client technologies
-
acquaintance with the field of industrial continuous processes
-
the roles involved with the life cycle of solutions developed using the LIBPF® enabling technology, see LIBPF® Technology Introduction
-
a general knowledge of the concepts of the LIBPF® high level Model User API, see LIBPF® Model User API manual
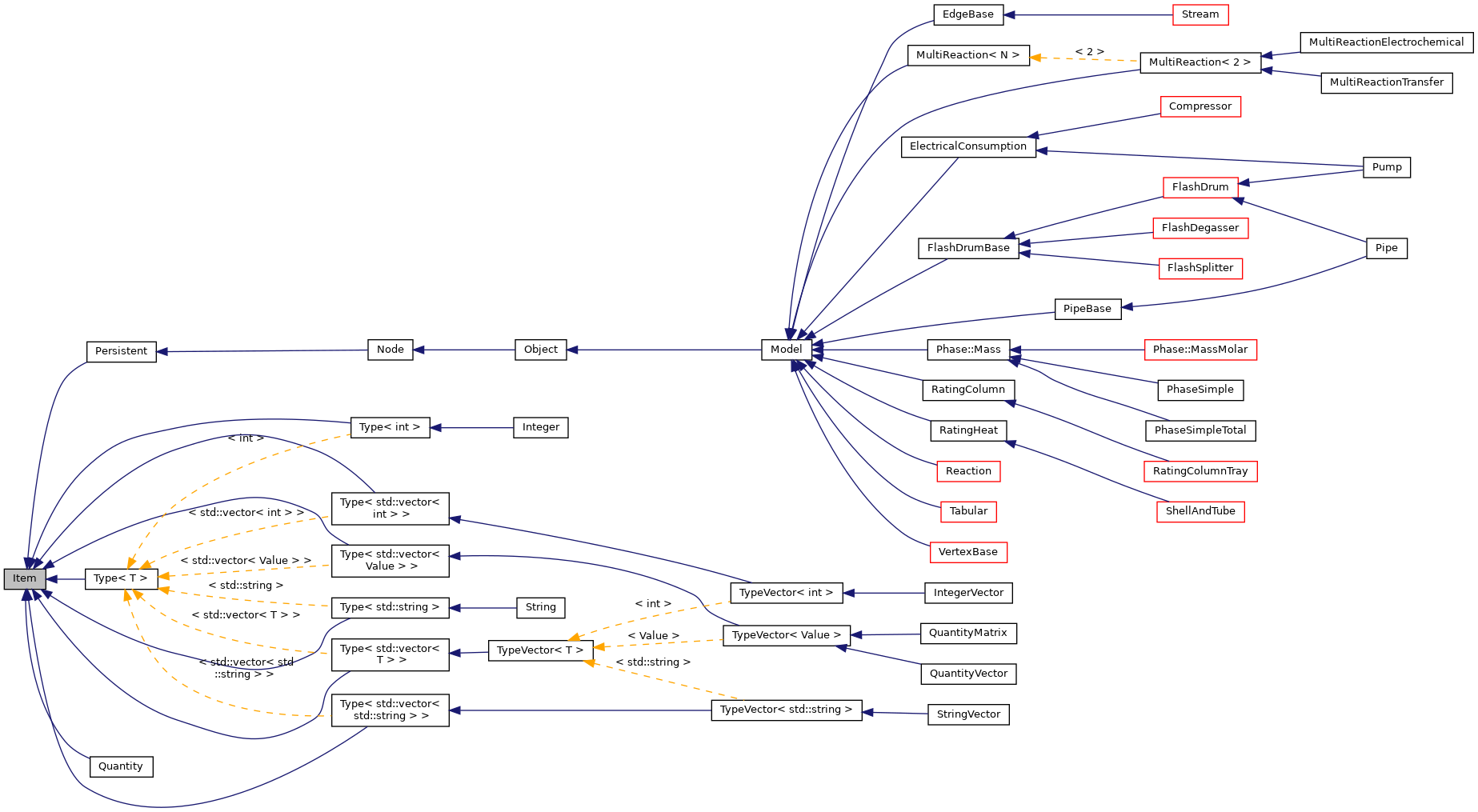
The Model class
The Model class is the base class from which all models in LIBPF® have to be derived.
It is built by progressively adding functionality in 6 steps:
-
Item, the common ancestor to Models but also to variables; has:
-
type
-
tag and description
-
a parent pointer to the forward-declared Persistent class (so that it can be part of a hierarchical data structure)
-
-
Variables - in LIBPF® we only have scalar variables (vector / matrix variables are explicitely considered as lists of scalars):
-
Integers
-
Quantities
-
Strings
variables add to Item the value field, that can be respectively : int, Measurable and std::string
-
-
Persistent - a semi-abstract class which represents an suitable to be persisted to database, i.e. equipped with an integer local id, unique within the tree
-
Node - a concrete class to represent a persistable node belonging to a hierarchical tree structure, used for a node belonging to a hierarchical tree structure and for the hierarchical tree structure itself. The important data members the Node class adds to Persistent are:
-
root: a pointer to the root Persistent Item of the tree
-
children: std::map storing the std::unique_ptrs to the direct descendant Nodes
-
-
Object - these are Nodes with variables; the variables are stored in separate std::maps as raw pointers. Accessor methods are provided for reflection and look-up based on tag strings.
-
Model - these are Objects that can be computed. They have interfaces like:
-
isFirstPass / setFirstPassRecursive / setFirstPass
-
calculate
-
maximumIterations
-
setup
-
initializeNonPersistents
-
…
-
The resulting class hierarchy overview is:
How to identify an object ?
Different mechanisms can be used, each with a different scope:
-
Tags are for humans
-
Node tags must be unique among siblings, i.e. within the direct descendants of a Node. Nothing bars duplicate tags at different locations in the hierarchy like in A:A:A:A or A:(B (A, B)). Therefore they can not be used to uniquely identify nodes in a tree
-
Full tags are unique in each tree, but nothing bars creating different trees with equally fulltagged Nodes
-
Variable tags are unique among each of the different variable groups (Q, S, I) of a Node: we can have T as a Quantitity, and as an Integer and as a String in the same Node
-
-
Pointers are for computers and are only valid at run-time
-
Local ids can be used to uniquely identify objects within a certain containing object with an integer
-
Each tree will have an independent id numbering scheme, always starting from 0
-
the ids of all descendant of a Node are in a known interval [rootId() .. (rootId() + range() - 1)]
-
If a tree is edited, and some nodes pruned, there will be holes in the sequence (i.e. the ids will be in the interval, but not contiguous); this is OK
-
-
Global ids are for databases, where they are primary keys
-
the database holds many trees: a forest
-
The primary key in the CATALOG table is an integer ID, unique among all nodes through all trees in the forest
-
Each tree will get an offset when first inserted into the database, to be stored in the root node
-
Subsequent calls to the update method can reuse this stored offset to find again the matching database IDs
-
When a tree object is copied, the offset is reset so that it gets inserted at a different location
-
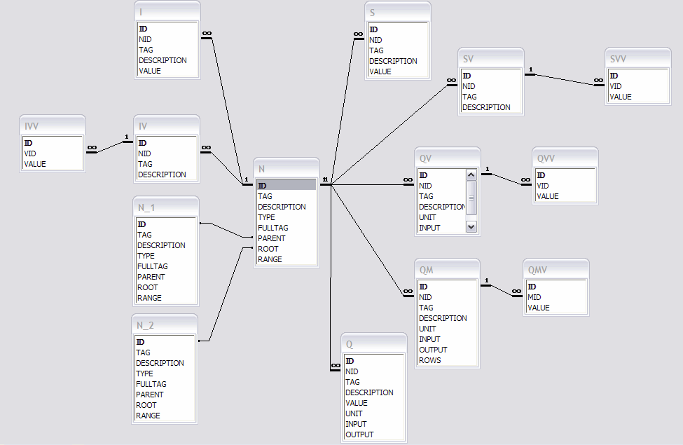
Database schema
The LIBPF® database contains the following tables:
-
N: nodes
-
I: integers
-
Q: quantities
-
S: strings
N: nodes table
-
ID: integer PRIMARY KEY (autonumbering)
-
TAG: character (50)
-
DESCRIPTION: character (255)
-
TYPE: character (50)
-
FULLTAG: character (255)
-
PARENT: integer REFERENCES N (ID)
-
ROOT: integer REFERENCES N (ID)
-
RANGE: integer
I: integers table
-
ID: integer PRIMARY KEY (autonumbering)
-
NID: integer REFERENCES N (ID)
-
TAG: character (50)
-
DESCRIPTION: character (255)
-
VALUE: integer
Relationships